Robots.txt contains the instructions for search engine bots.
It is a simple file, but it is easy to mess it up.
And if you do, it can dramatically hurt your SEO.
Are you worried? Don’t be.
This post has you covered. It will show you everything you need to know about it.
Contents:
What Is Robot.txt?
Robot.txt is a text file that suggests search engine robots which pages on your website to index and which ones to ignore.
 The biggest search engines like Google, Bing, and Yahoo support its use.
The biggest search engines like Google, Bing, and Yahoo support its use.
You can find it in the root directory of your website, and it should be named “robots.txt”.
However, as stated by Google, you should know that:
It is not a mechanism for keeping a web page out of search engine results.
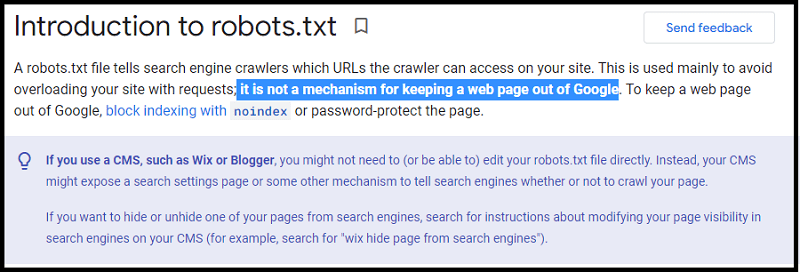
So, to keep your pages out of Google, you should use the “noindex” tag.
Now, do you want to know how robot.txt works?
Here is an example of what it looks like:
User-agent: * Disallow: /wp-admin/ Allow: /wp-admin/admin-ajax.php
This tells all search engine robots that they are not allowed to index any pages in the /wp-admin/ directory.
On the other hand, they are allowed to index the admin-ajax.php page.
Again, it’s important to underline that there’s no way to ensure that content will be excluded from search results using the robots.txt file, according to Google’s Webmaster Central Help Center.
If other pages point to your page with descriptive text, Google could still index the URL without visiting the page.

 Important note: to block pages from appearing on search engine results, you should use robot meta tags.
Important note: to block pages from appearing on search engine results, you should use robot meta tags.
Is Robots.txt Important for SEO?
Well, most websites don’t need it.
It’s because Google can index your website without one.
It will also automatically not index duplicate pages or pages they find not important.
With this in mind, these are the three main reasons why you should have a robots.txt file:
- Block Private Pages
- Prevent Resources from Being Indexed
- Maximize Crawl Budget
Block Private Pages
If you have pages on your website that you don’t want to be indexed, you can block them with robots.txt.
 This is useful if you have pages that are for logged-in users only. You don’t want search engines to index these pages because they won’t be relevant to anyone who isn’t logged in.
This is useful if you have pages that are for logged-in users only. You don’t want search engines to index these pages because they won’t be relevant to anyone who isn’t logged in.

Or, for staging pages. If you’re working on a new page or redesigning an old one, you can also block it with this file until it’s ready to be published.
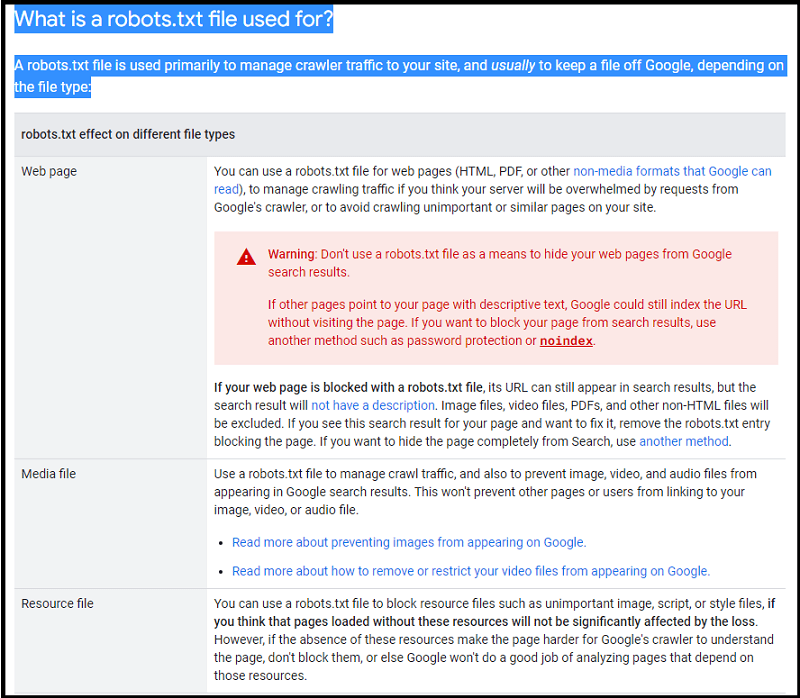
Prevent Resources from Being Indexed
Another common situation is to prevent search engines from indexing certain resources on your website.
It is usually done to save server resources or to prevent duplicate content from being indexed.
For example, you might have an image gallery that is generating a lot of traffic but not getting any leads or sales. In this case, you might want to block it.
Maximize Crawl Budget
Last but not least, it can be used to help maximize your crawl budget.
Your crawl budget is the number of pages on your website that search engine robots can and will index.
If you have a large website with thousands of pages, you might want to use robots.txt to block some of the less important pages. This will help the search engine robots focus on the most important ones, which can help improve your overall SEO.
Robots.txt User-Agents and Directives
Robots.txt files consist of two parts: user-agents and directives.
User-Agents
User-agents are the search engine robots that the file is meant for.
The most popular ones are:
- Google: Googlebot
- Bing: Bingbot
- Yahoo!: Slurp
- Baidu: Baiduspider
- DuckDuckGo: DuckDuckBot
Tip: use the star (*) wildcard to match all user-agents.
Here is an example:
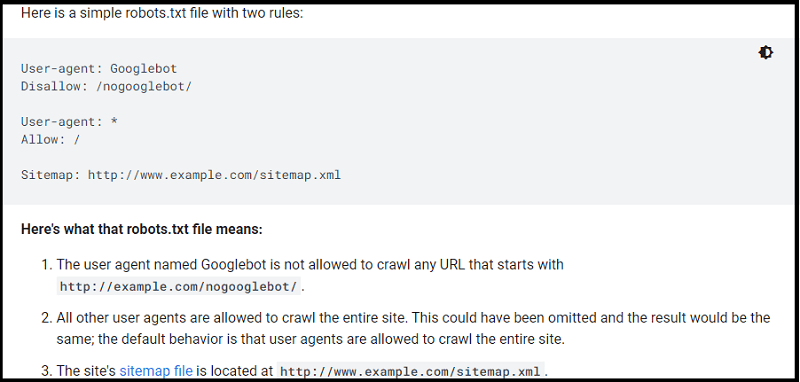
User-agent: * Disallow: /wp-admin/ Allow: /wp-admin/admin-ajax.php
This file will apply to all search engine robots.
Directives
There are three directives that Google currently supports:
- Disallow
- Allow
- Sitemap

Disallow
The Disallow directive tells the search engine robots not to index specific pages or resources.
For example, if you want to block the /wp-admin/ directory from being indexed by all search engines, you would use this directive:
User-agent: * Disallow: /wp-admin/
Allow
The Allow directive is the opposite of Disallow. It tells search engine robots that they are allowed to index certain pages or resources.
For example, if you want to allow the /wp-admin/admin-ajax.php page to be indexed, you would use this directive:
User-agent: * Disallow: /wp-admin/ Allow: /wp-admin/admin-ajax.php
Sitemap
The Sitemap directive tells the search engine robots where they can find your sitemap.xml file. This is a file that contains a list of all the pages on your website.
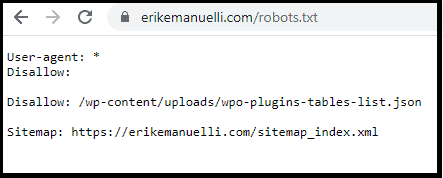
For example, if your sitemap.xml file is located at /sitemap_index.xml, you would use this directive:
User-agent: * Disallow: /wp-admin/ Allow: /wp-admin/admin-ajax.php Sitemap: https://erikemanuelli.com/sitemap_index.xml
How to Find Your Robots.txt File
Robots.txt files are located in the root directory of your website.
Usually, if your website is example.com, the file would be placed at example.com/robots.txt.
Tip: if you can’t find it on your website, you can use a Chrome extension to help you out.
How to Create a Robots.txt File
It is quite easy!
Just create a new text file and name it “robots.txt”.
You can use simple programs like Windows Notepad.
Then, add your directives to the file.
For example:
Save the file and upload it to the root directory of your website. That’s it!
If you need further help, Google has an extensive guide here.
Robots.txt in WordPress
If you’re using WordPress, some plugins can help you manage your robots.txt file, like Yoast SEO and All in One SEO Pack.
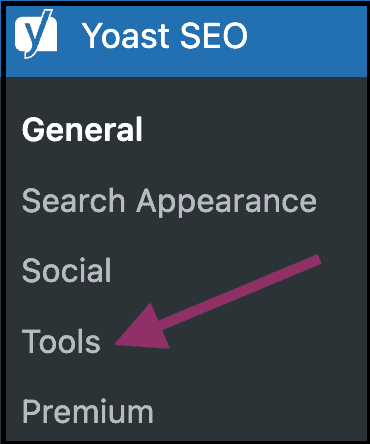
To create or edit a new one using the Yoast SEO plugin, go to your WP dashboard, and click on ‘Yoast SEO’ in the admin menu.
Click on “Tools”:
Important: you should have enabled “File Editing”.
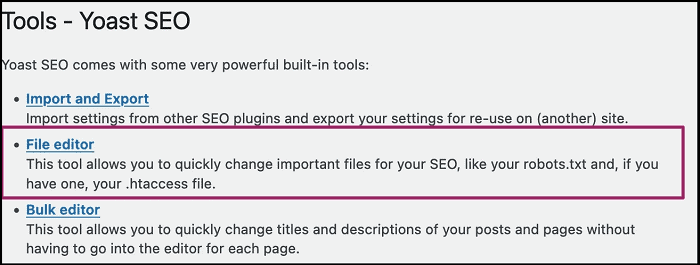
Click on “File Editor”:
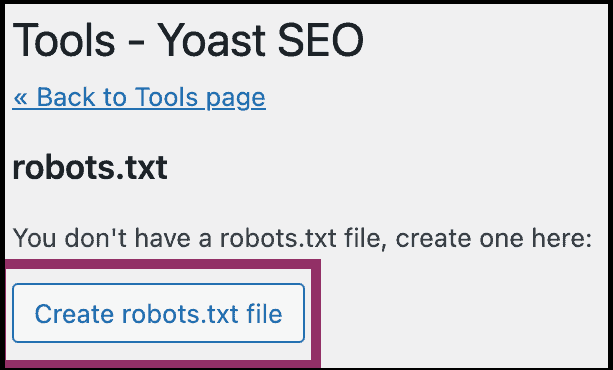
Here, click the “Create robots.txt file” button:
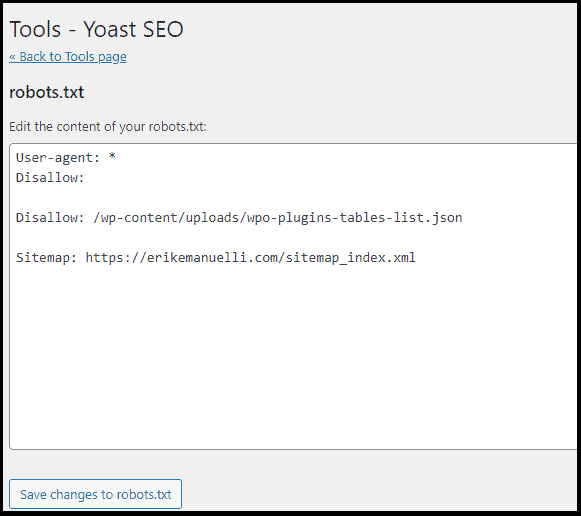
Finally, you can view or edit your file:
Robots Meta Tags vs Robots.txt Files
What’s the difference between robot meta tags and robots.txt files?
The first one is HTML codes that you can add to your website’s pages. They give search engine robots instructions on whether to index a page and follow the links on that page.
For example, if you don’t want to index a page, you would use this tag:
<meta name=”robots” content=”noindex”>
And if you want to index a page but don’t want to have some of the links followed, you would use this tag (the anchor text is the clickable words used for the link):
<a href=”URL” rel=”nofollow”>ANCHOR TEXT</a>
Neither of these tags will block resources like images or CSS files from being indexed.
In short, robot meta tags apply to only the page containing the instructions, while robots.txt is applied to the entire site.
Robots.txt Report
Google used to have a tester tool to check the robots.txt file.
Today, it is embedded as a feature on Google Search Console.
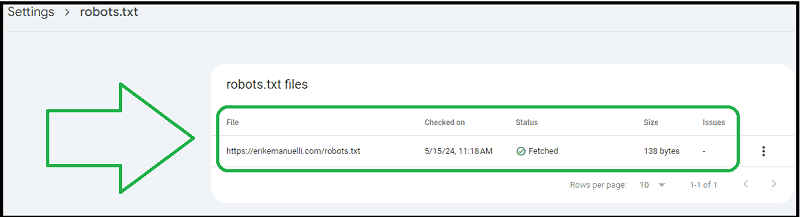
You can simply click here to directly access to yours.
FAQs
Q: Why is robots.txt blocked?
A: There are several reasons why robots.txt might be blocked. The most common ones are wrong permissions, incorrect syntax, or a misconfigured server. Make sure to check your file’s syntax and correct any mistakes before uploading it to the root directory of your website.
Q: Is robots.txt a vulnerability?
A: No, robots.txt is not a vulnerability in itself. However, if you are using it to block sensitive pages or resources, attackers may try to access them even though they are blocked by the file.
Q: Is robots.txt the same as sitemap?
A: No, robots.txt and sitemaps are two different things. Robots.txt is a text file that tells search engine robots which pages or resources they can index. Sitemap is an XML file that contains a list of all the pages on your website. You should use both together to maximize your SEO performance.
Q: Are robots.txt files still used?
A: It’s not mandatory. But it’s still a good practice to create and upload one, especially if you want to control which pages or resources search engine robots can index.
Q: What is the limit of a robot.txt file?
A: The limit of a robots.txt file depends on the search engine you are targeting. Generally, it should not exceed 500KB in size. If it’s larger than that, some robots may not be able to process it correctly.
Before You Go
If you have come this far, you should have learned more about technical SEO.
But wait. This does not end here.
There’s much more to know about. You may want to read:
So, now it’s over to you.
Do you have any questions?
Feel free to leave a comment below.
And don’t forget to share the article, if you liked it!
Hi Erik
What a joy to be here again after a bit gap. 😊 I am so glad that I am back here to check an amazing and informative post on Robots.txt.
A well explained post on the subject, I never knew it’s important in relation to SEO. It’s really good to know that the biggest search engines like Google, Bing, and Yahoo all support its use.
Thanks Erik for this educational piece.
Hope you are doing good 😊
Best
~ Phil
Thanks for visiting and commenting, Philip.
Good to hear you liked this guide.
Nicely Explained A to Z, Thanks.
Thanks for the feedback, Nauraj.