Duplicate content can be an SEO issue.
If you are not careful, it can tank your website’s search engine rankings and cause you to lose traffic.
This post will explain what it is, how it hurts your online visibility, and how to avoid it.
Contents:
What Is Duplicate Content?
Duplicate content is when you have the same or very similar content on more than one page on your website or you have copies of other’s website content on your site.
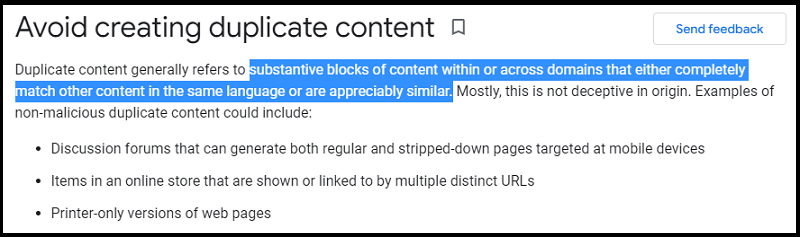
It’s defined by Google as:
substantive blocks of content within or across domains that either completely match other content in the same language or are appreciably similar.
How Does Duplicate Content Hurt SEO?
Duplicate content can hurt your SEO, because:
- It confuses search engines
- It splits link equity
- It can get you penalized
- It can waste your crawl budget
It Confuses Search Engines
When search engines crawl your website, they want to easily understand what each page is about.
If they see the same or very similar content on multiple pages, it will be difficult for them to determine which one is most relevant for a given query.
This may lead to lower search engine rankings for those pages.
👉 In fact,
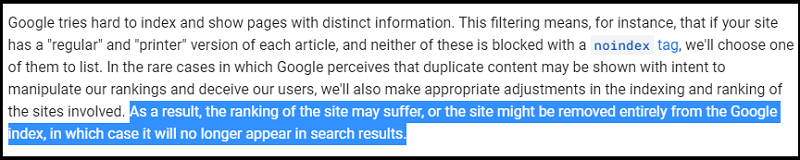
Google tries to index and show pages with different information.

It Splits Link Equity
Link equity is the authority that a backlink passes from one webpage to another.
When you have duplicate content, other sites that want to link to you have to choose between these duplicates.
This way, the link value gets split between the pages, rather than being concentrated on one page.
In a few words?
You won’t reach the search engine ranking you would:
It Can Get You Penalized
If Google detects that you are deliberately trying to game the system by creating duplicate content, they may penalize your website with a lower search engine ranking:
✅ However, this is extremely rare and it only happens if your site is acting deceptive and manipulating search engine results:

It Can Waste Your Crawl Budget
The crawl budget is the number of pages that a search engine will visit on your website during a given period.
If you have duplicate pages, the search engine will likely access the same content multiple times, which is a waste of your crawl budget.
When Does Duplicate Content Happen?
There are a few scenarios where duplicate content can happen.
For example, when you have:
- Multiple pages on your website with the same or similar content
- Content copied without permission
- WWW and Non-WWW-pages (Including HTTP and HTTPS)
Multiple Pages With Similar Content
Pay attention to your website architecture. If you have multiple pages with the same or similar content, you may have a keyword cannibalization issue.
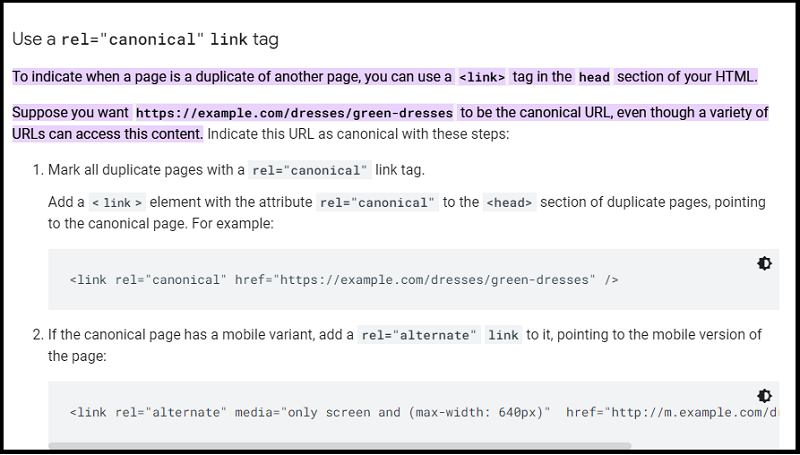
Therefore, it’s important to tell Google which page you want them to index. You can do this by using a rel=canonical tag.
For example, let’s say you have two pages on your website:
- Page A: example.com/page-a
- Page B: example.com/page-b
Both of them have the same or similar content.
To avoid duplicate content issues, you would add a rel=canonical tag to Page B that points to Page A.
💡 This tells Google that Page A is the canonical or master version of the page, and they should index that one instead.
Content Copied Without Permission
If you find that someone has copied your content without permission, there are a few things you can do:
- Reach out to the site owner and ask them to remove the duplicate content. This is usually the quickest and easiest way to get rid of the copied content. Reach out to the website owner and politely ask them to remove it.
- File a DMCA complaint. If the website owner does not respond or remove the stolen content, you can file a Digital Millennium Copyright Act (DMCA) complaint. This is a formal notice that asks the hosting company to remove the infringing content.
- Add a rel=canonical tag to your original content. This tells Google that yours is the canonical or master version, and they should index that one instead.
WWW and Non-WWW-pages (Including HTTP and HTTPS)
Another common issue is when you have both a WWW and non-WWW version of your website.
For example:
- WWW: https://www.example.com
- Non-WWW: https://example.com
If you don’t redirect one to the other, Google will see these as two separate websites with the same or similar content. This can cause issues.
To avoid this, you should set up a 301 redirect from the non-WWW to the WWW version or vice versa.
Another common situation is having both a secured version of HTTPS and a non-secured HTTPS version of your website. For example:
- Secured: https://example.com
- Non-secured: http://example.com
👉 If both versions are live and visible to search engines and you don’t redirect one to the other, Google will see these as two separate websites with the same or similar content.
How to Avoid Duplicate Content
The best way is to make sure that each page on your website has unique and original content.
That said, there are a few other things you can do:
- Use canonical tags
- Syndicate Carefully
- Use 301 redirects
Use Canonical Tags
A canonical tag tells search engines which version of a piece of content is the original and should be indexed.
This is helpful if you have very similar pages or if you need to republish content from another source.
✅ Here’s how to specify a canonical page, according to the documentation found at Developers.Google:
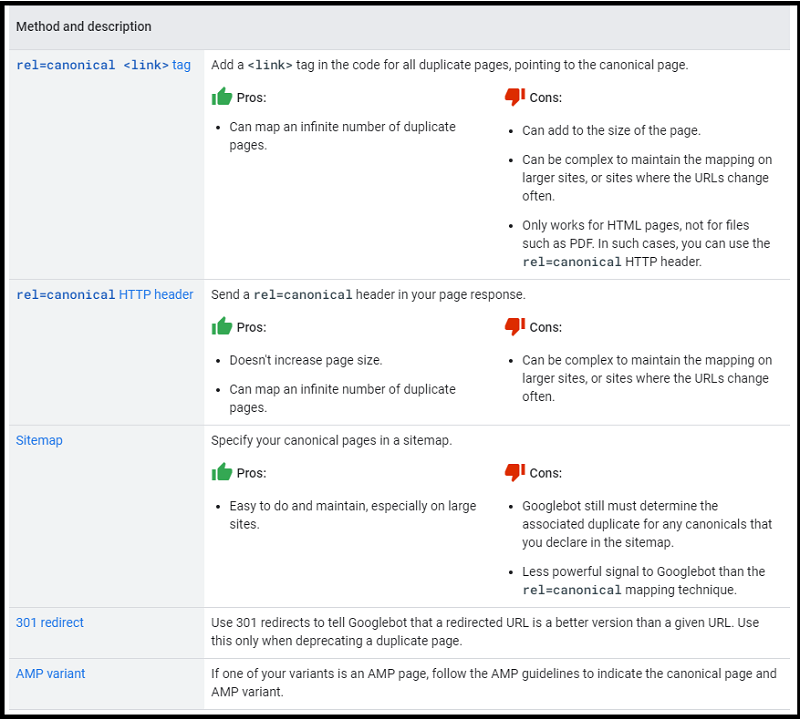
Note that if you need help finding the canonical tags on your pages, you can use the Moz Chrome extension.
Syndicate Carefully
If you syndicate your content (meaning you publish it on other websites), be careful to add a rel=”canonical” tag to the syndicated version.
This will tell search engines that the original version of the content is on your website.
💡 Remember that Google says that will always show the version it thinks is more appropriate (which may or may not be the version you would like):

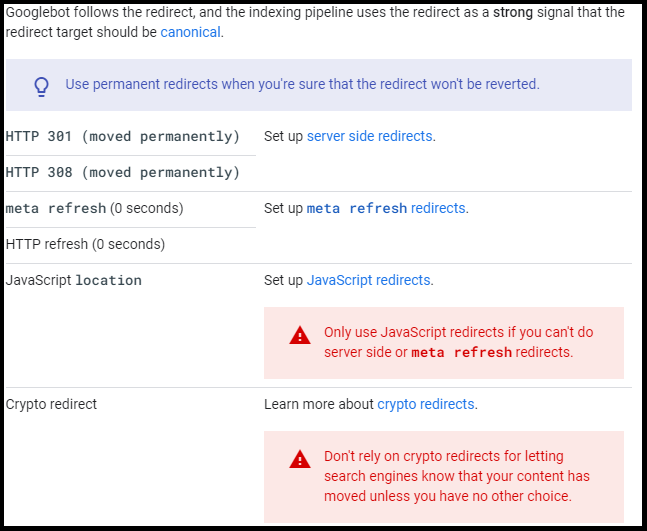
Use 301 Redirects
A 301 redirect is a way of permanently forwarding one URL to another.
This is helpful if you need to redirect traffic from an old page to a new page.
Duplicate Content FAQs
Q: How much duplicate content is acceptable?
A: There is no specific percentage of duplicate content that is acceptable. Generally speaking, the more unique and valuable your content is, the better it will perform on search engine results pages.
Q: Is there an app to check if the content is copied?
A: Yes, many apps can help you check if the content is copied from another source. Some of the most popular ones include Copyscape and Grammarly. These tools will scan your website’s content and flag any sections that appear to be duplicated from somewhere else.
Q: What happens if you copy content from another website?
A: If you copy content from another website without permission, it’s considered plagiarism and can lead to legal issues. It can also damage your reputation and hurt your online visibility if search engines detect the copied content. It’s always best to create original content or properly cite and link back to the source whenever possible.
Q: What’s Google’s take on duplicate content?
A: Google advises site owners to avoid creating duplicate content whenever possible. According to the Google Search Central:
Duplicate content on a site is not grounds for action on that site unless it appears that the intent of the duplicate content is to be deceptive and manipulate search engine results.
Before You Go
Duplicate content can be an SEO nightmare if you’re not careful.
By understanding what it is and how it hurts your website, you can take steps to avoid it.
✅ Also, did you know that you can use an advanced command to find duplicate content?
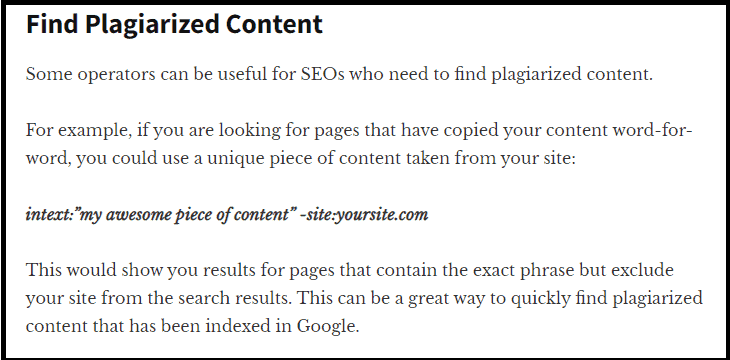
But wait!
How can you create great content that users and Google will love?
Here are some helpful guides you may want to read:
Now, it’s over to you.
Thanks for reading!
And if you have any questions, feel free to drop them in the comments below!
Hello Erik,
You nailed it!
Duplicate content is a big challenge for every genuine blogger. People who don’t want to create their own content simply copy-paste others’ content and think that they can rank well. Search engines are smart enough now to understand duplicate content. Great Post Man.
Regards,
Vishwajeet Kumar
Hi Vishwajeet,
other than avoiding copying content from other sources,
it’s important to understand how your own site can create duplicate content if you mess up some technical “stuff”.
Thanks for reading and commenting!
Hi Erik,
So glad to be here again after a long gap. Hope you are doing good.
I am here today via BizSugar wherein this content is curated,. and i upvoted. and commented.
A well written post on duplicate content and it’s bad effects on our websites especially in the SEO part.
Oh, my i need to check this out on my site as i have several contents on the same subject especially on the subject “Blog Comments”
I need to fix this by using your this like the canonical tags and the 301 directs.
Thanks Erik for the timely warning.
Keep sharing.
Best
~ Phil
Maybe it’s more about keyword cannibalization, than duplicate content, Phil.
Thanks for check-in and comment the post!
Publishing dupe content can be a big time problem Erik. Basically, it is cheating. Imagine how easy blogging would be if it were publishing one post than spreading it across 1000 blogs? Imagine how terrible the quality of posts would become if it were acceptable to just write one post and then to duplicate it? Genuine content or nothing else.
The concept of “efforts” taken by bloggers to create content has been covered widely in the new Google guidelines (used by raters to assess the quality of a website):
https://erikemanuelli.com/google-e-e-a-t/
No wonder why content originality is so important!