The crawl budget falls in the technical aspect of your website.
It may sound boring, but it’s something you should know.
So, do you want to know more about it?
Let’s dive in!
Contents:
What Does Crawl Budget Mean for Googlebot?
To put it simply, the crawl budget is the number of pages that Googlebot can and wants to crawl on your website.
This number is determined by a few factors, including:
- The size of your website
- The speed of your pages
- How often does your site’s content change
- How many other domains link to yours
- Your crawl rate limit (the maximum number of pages that Googlebot can crawl on your site per day)
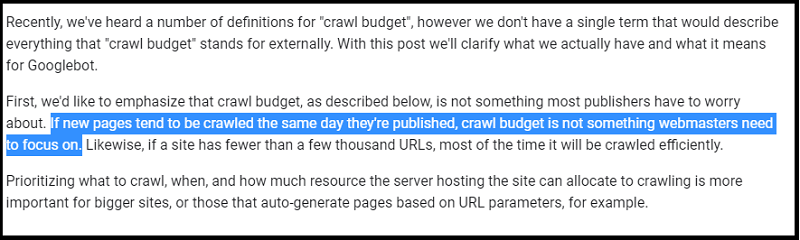
Google states that:
If new pages tend to be crawled the same day they’re published, crawl budget is not something webmasters need to focus on.
✅ In a few words, if you don’t have a big site, with thousands of URLs, you don’t have to worry about it.
However, if you want to know more about it, keep reading!
Why Is Crawl Budget Important for SEO?
The crawl budget is not a ranking factor, but every site owner should know how it works.
It is important for SEO because:
- It affects how often your website is crawled by search engine bots. If your content isn’t crawled frequently enough, it won’t be indexed as often, and you could miss out on ranking opportunities.
- It also impacts the freshness of your content. If your website is crawl budget-constrained, it’s more likely that your content will be stale and outdated. This can negatively impact your rankings (as search engines prefer to index fresh, relevant content).
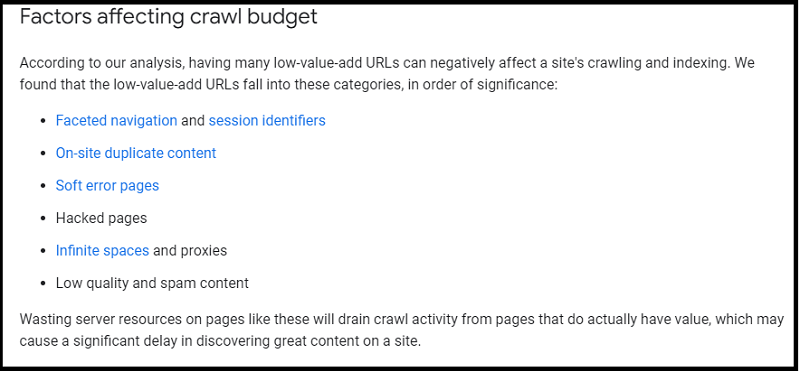
Factors Affecting Crawl Budget
Some of the factors that can impact your crawl budget include:
- Faceted navigation and session identifiers
- On-site duplicate content
- Soft error pages
- Hacked pages
- Infinite spaces and proxies
- Low-quality and spam content
Faceted Navigation and Sessions Identifiers
Faceted navigation is a type of website navigation that allows users to narrow down their search results by selecting various filters.
Session identifiers are unique IDs that are assigned to users when they visit a website.
Both of these can cause crawl budget issues because they generate a large number of URLs that serve the same content.
This can lead to search engine bots crawling your website inefficiently, using up valuable resources without providing any new or relevant information.

On-Site Duplicate Content
Duplicate content is another common issue that can occur on websites (especially larger ones).
This happens when the same content is accessible via multiple URLs.
For example, if you have a blog post that can be accessed at both example.com/blog-post and example.com/blog-post?id=123, this would be considered duplicate content.
Not only does this cause Googlebot issues, but it can also lead to decreased rankings in SERPs.
Soft Error Pages
Soft error pages are pages that return a 404 error or other HTTP error codes, but the content of the page is still accessible.
This can happen when a website’s URL structure changes and old URLs are no longer valid, but they haven’t been redirected to the new URL.
As a result, search engine bots crawl these pages, using up valuable crawl budgets without finding any new or relevant information.
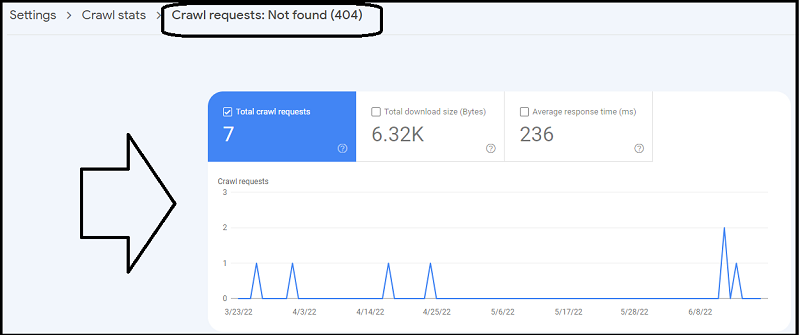
You can check the Crawl requests: Not found (404) in Google Search Console, under Settings->Crawl stats:
Hacked Pages
If your website has been hacked, there will likely be a large number of malicious URLs added to your site.
These pages can consume a lot of crawl budget without providing any value.
In addition, these pages can also negatively impact your rankings as they often contain spammy or low-quality content.
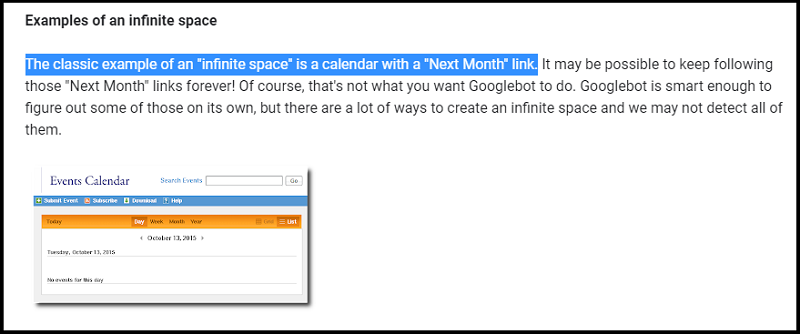
Infinite Spaces and Proxies
Infinite spaces are pages that contain an infinite amount of content, such as a search results page.
This can happen when there is a bug on the website that generates an infinite number of results.
For example, proxies act as an intermediary between users and other websites.
They can also cause crawl budget issues as they often generate a large number of URLs that serve the same content.
Low-Quality and Spam Content
Low-quality or spammy content can also consume the crawl budget without providing any value.
This type of content is often generated by bots and is not relevant to users.
As a result, it’s important to ensure that your website doesn’t contain any low-quality or spammy content.
How Can I Check My Crawl Budget?
Do you know that the Google Search index contains hundreds of billions of web pages and is well over 100,000,000 gigabytes in size?
That’s quite a big work for Googlebot!
So, how can you check if your content has been crawled by Google?
💡 There is a simple way to do it, using Google Search Console.
Go to Settings -> Crawl Stats:
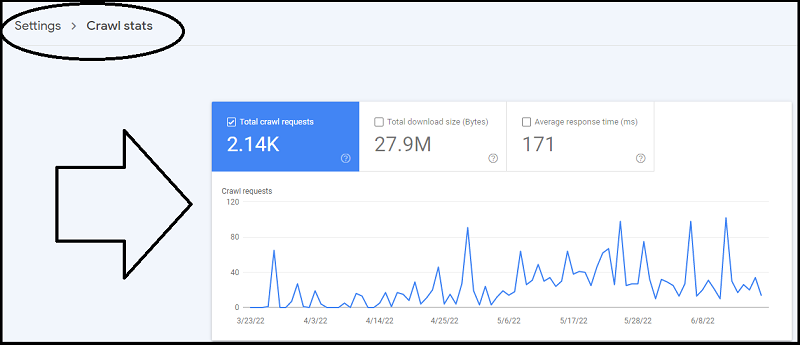
Here, you can see the average number of pages that Googlebot crawls per day.
You can also see how many kilobytes of data were downloaded, and the average response time of your hosting.
Clicking on “Host Status“, you can see if your host had problems in the past:
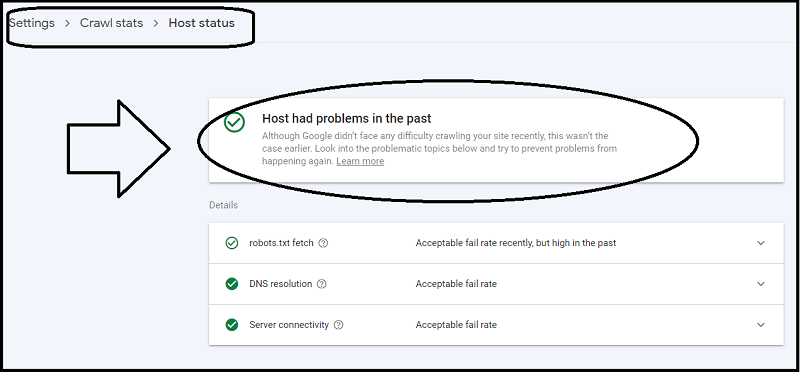
You should see a green mark.
👉 If you have a red mark on your host status, you need to check your:
- Robots.txt availability
- DNS resolution
- Host connectivity
Here’s a breakthrough of all the messages you can encounter:
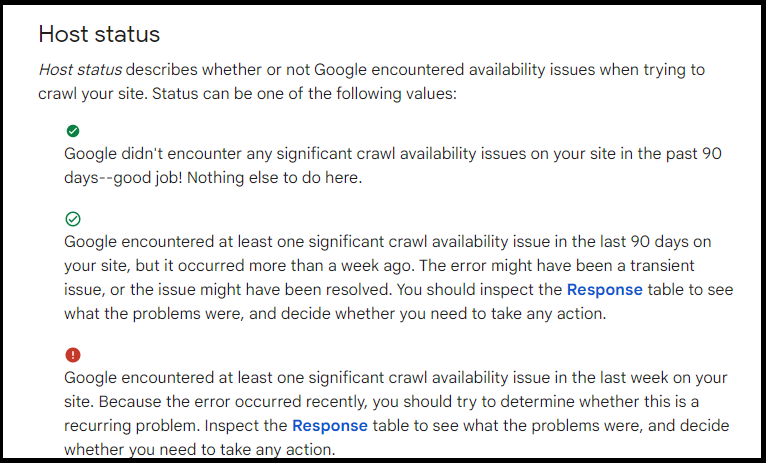
In the crawl stats page, you can also check the crawl requests breakdown, by:
- Response
- File type
- Purpose
- Googlebot type
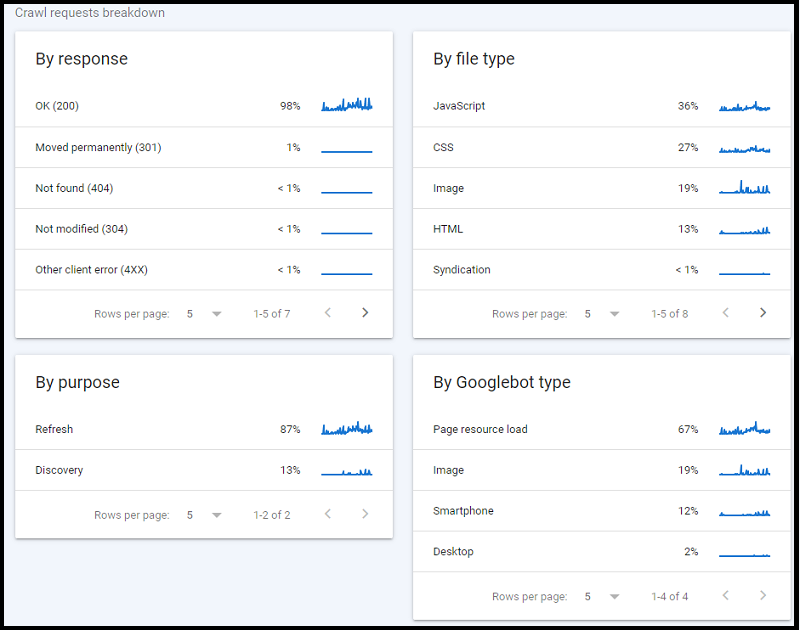
And look out for any issues.
How to Optimize Your Crawl Budget
Follow these best practices:
- Internal linking
- Use a sitemap
- Proper use of robots.txt
- Improve your website speed
- Write fresh and up-to-date content
- Use a flat website architecture
Internal Linking
One of the best things that you can do to improve your crawl budget is to ensure that your website has a good internal linking structure.
Internal links are links that point from one page to another one, within your website.
And they help search engine bots crawl your site by providing them with a path to follow.
In addition, they also help to distribute link equity throughout your website.

Use a Sitemap
A sitemap is an XML file that contains all of the URLs on your website.
It helps search engine bots crawl your site by providing them with a list of all your pages.
Proper Use of Robots.txt
Robots.txt is a text file that contains instructions for search engine bots.
It is really important because it helps to control how these bots crawl and index your website.
For example, one of the things that you can do with it is to specify which pages you do not want to be crawled.
This can help optimize your crawl budget by preventing search engine bots from crawling pages that don’t contain any new or relevant information.
Here are a few examples of valid robots.txt URLs:
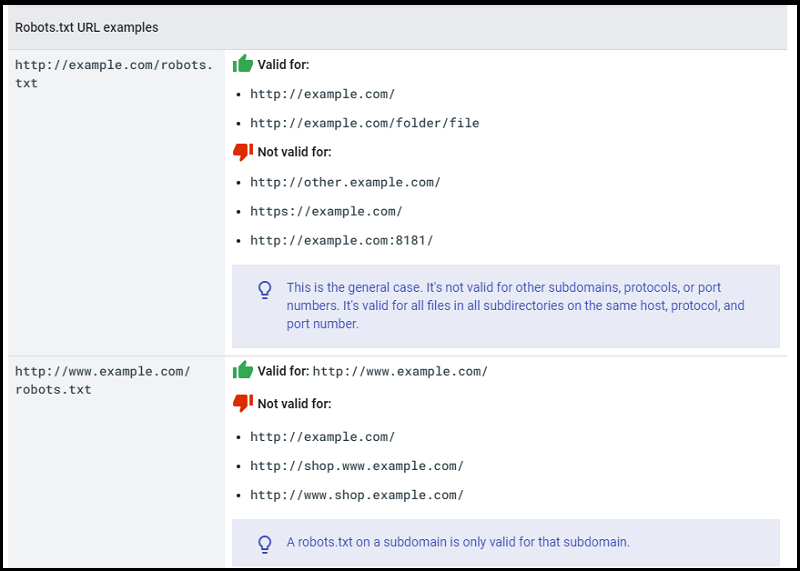
Improve Your Website Speed
Another great way to optimize your site is to improve your loading speed.
Search engine bots crawl websites at a much slower rate than users.
In fact, if yours is not loading well, it will take longer for these bots to crawl all your content.
Write Fresh and Up-to-Date Content
Search engine bots crawl websites more frequently when they contain new or updated information.
As a result, by writing fresh and up-to-date content, you can help to ensure that your pages are crawled more often.
Use a Flat Website Architecture
One last optimization strategy is to use a flat website architecture.
This is one in which all of your pages are accessible from the home page.
And it helps search engine bots access your site more efficiently as they don’t have to crawl through many links to find the information they’re looking for.
Crawl Budget FAQs
Q: Crawl errors and crawl budget: are they ranking factors?
A: No, crawl errors and crawl budget are not ranking factors.
However, they can affect your SEO performance in the sense that they may stop search engine bots from crawling and indexing your content.
Q: How often should my site be crawled?
A: This depends on how often you update your website. If you make frequent updates, then your website should be crawled more often. If you don’t update your content very often, then it may be fine to let search engine bots crawl your website less frequently.
Q: How do I determine my website’s crawl budget?
A: Your website’s crawl budget is determined by several factors such as the size of your website, its content, and the speed of your server. To find it out, you can use Google Search Console to see how much time is spent on each page by search engine bots.
Q: How do you control a crawl budget?
A: You can control your crawl budget by ensuring that your website has a good internal linking structure, using a sitemap, making sure to use robots.txt properly, improving your website speed, writing fresh and up-to-date content, and using a flat website architecture.
Q: How does crawl work?
A: Crawl works by search engine bots accessing websites and looking for new or updated content. They use the instructions provided in the robots.txt file to determine which pages they should crawl, and use their internal algorithms to decide how often they should crawl each page on your website. Additionally, a sitemap can be used to provide them with a list of all of the pages on your website. This helps ensure that all of your pages are properly indexed and crawled efficiently.
Q: What is crawling vs indexing?
A: Crawling refers to the process of searching for new or updated content on a website, whereas indexing involves adding that content to the search engine’s database. When a website is crawled by search engine bots, they look for new or updated pages and then evaluate if it’s worth adding them to their index.
Q: What is the crawl rate?
A: The crawl rate is the rate at which search engine bots crawl your website. It can vary from website to website and can be affected by several factors such as the size of your website, its content, and the speed of your server. You can use Google Search Console to see how frequently your site is crawled.
Q: What is the crawl budget limit?
A: The crawl budget limit is the maximum amount of resources that a search engine has allocated for crawling your website. If your website exceeds this limit, then search engine bots may not be able to fully crawl and index all of your pages. To ensure that your crawl budget is used efficiently, it’s important to optimize your website accordingly.
Q: How can I make Google crawl faster?
A: To make Google crawl faster, you can ensure that your website has a good internal linking structure, use a sitemap, make sure to use robots.txt properly, improve your website speed (improve your hosting resources), write fresh and up-to-date content, and use a flat website architecture.
Before You Go
Thanks for reading so far! At this time, you should have learned a lot about the crawl budget.
But wait! This is just one part of the equation.
Technical SEO is complex and involves a lot of different factors, such as:
- Robots.txt and SEO: All You Need to Know [Practical Guide]
- Canonical Tags: Beginner’s Guide [Avoid Duplicate Content]
- Redirects: How to Use Them for SEO [The Complete List]
- HTTP Status Codes: The Full List [And How to Handle Them]
- Website Architecture: 9 Simple Strategies to Improve Your Site Structure
Following all of these best practices will help to ensure that your website is optimized for search engine bots, which can ultimately help improve your website’s visibility in search engine results.
Now, over to you.
Do you have any questions?
Leave a comment below and let me know!
I’m always happy to help.
Hi Erik,
Although many bloggers don’t have to worry about crawl budget, it’s essential for SEO because if your pages don’t get indexed, they won’t rank on SERPs. So, to ensure Google indexes your pages, it’s necessary to optimize for the crawl budget. And your tips for crawl budget optimization are well-founded. I also want to add that avoiding orphaned pages on your blog is one of the best ways to optimize the crawl budget.
Remember, an orphaned page is a blog post/page with no inbound links or internal links pointing to it. It’s all by itself (unlinked) as an outcast, so to speak.😀 So Google cannot quickly find such pages on your blog, hindering your SEO effort. To avoid having orphaned pages, guarantee to link internally and externally to all your blog posts. It helps you maximize your crawl budget and make Google bots find your pages quickly.
Another hack is to avoid duplicate content. If you already have duplicated content on your blog, limit them to the minimum because it negatively impacts your crawl budget. Google finds it challenging to index different pages with the same content. Search engine spider will have to figure out which of those same pages is the most relevant and informative.
Thank you for sharing, Erik!😁
Hi Moss,
good to see you!
You collected and summarized some of the best tips for technical SEO optimization.
I appreciated you stopping by, visiting, and commenting. 🙂
Learning will always be a continuous process.
This is an eye opener information.
Will consider this as well for my blog.
Thanks for this post.
Glad this post has helped you learn more about the crawl budget.
Thanks for visiting and commenting, Kingsley.